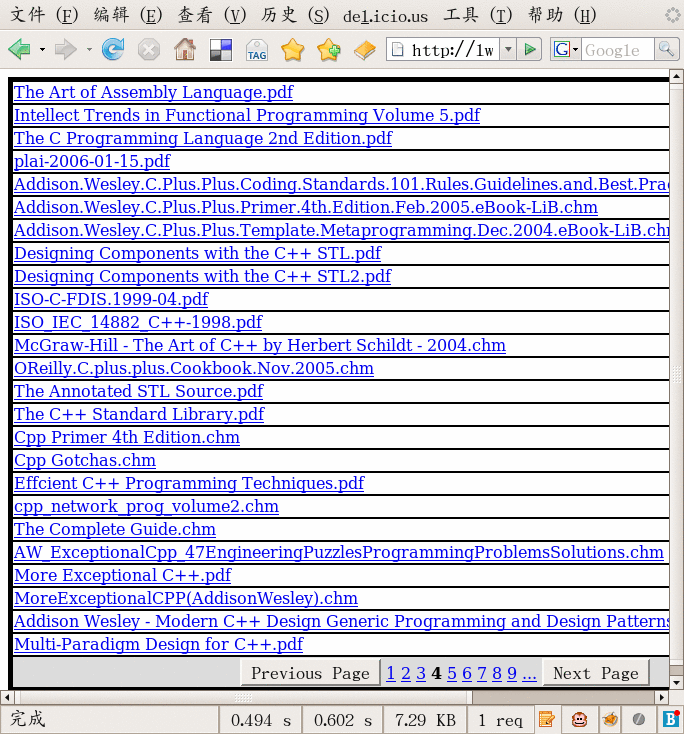
使用HTML::Pager可以写一个列出电子书的cgi小程序,在此基础上,可以很容易地增加文件名搜索功能。
首先增加搜索框和按钮,只需修改最后的打印语句:
my $title = "Book List ($num_of_books)";
print $cgi->header,
$cgi->start_html($title),
$cgi->h3($title),
$pager->output,
$cgi->h3('Book Search'),
$cgi->start_form,
$cgi->textfield('search'),
$cgi->submit,
$cgi->end_form,
$cgi->end_html;
接下来要构造搜索匹配字符串表,当输出框内为空时,搜索结果与以前一样,否则搜索结果应该包括所有用户提供的单词,为了简单起见,我们认为单词由空格分隔,暂不考虑引号。
my $cgi = CGI->new;
my @search_pattern = (qr/.(?:chm|pdf)$/i);
if ($cgi->param('search')) {
push @search_pattern,
map { qr/Q$_E/i }
split('s+', $cgi->param('search'));
}
my @books;
sub search_book {
for my $pattern (@search_pattern) {
return unless $_ =~ /$pattern/;
}
push @books, $_;
}
find( { wanted => &search_book, no_chdir => 1 }, '.');
程序截图如下: